
MobileNets v1
用于移动视觉应用的高效卷积网络
文献中引用的一些压缩方法,例如 production quantizationm, hashing, pruning, vector quantization 和 huffman coding 感觉值得了解一下(乘积量化,哈希,剪枝,矢量量化,哈夫曼编码)。至于SqueezeNets 等可以单独学习一下。Distillation(蒸馏)啥的也需要学学,还有Low Bit Networks(低比特网络)。啥也不会。。。orz
此外一些觉得不错的讲解,视频等等:
Abstract
提出了一类可以i用于移动和嵌入式视觉应用的高校模型,称为 MobileNets。MobileNets基于流线型架构,使用深度可分离卷积构建轻量级深度神经网络。引入了两个简单的全局超参数,可以有效的权衡延迟(latency)和准确性(accuracy)。这些超参数允许模型构建者根据问题的约束条件为他们的应用选择合适的模型尺寸。在 ImageNet 分类上,进行了大量的资源和精度权衡实验,并与其他流行的模型进行对比,模型都表现出了很强的性能。最后,在广泛的应用和示例中演示了 MobileNets 的有效性,包括目标检测,细粒度分类,人脸属性和大规模地理定位。
Introduction
自从AlexNet 在 ImageNet 挑战赛(ILSVRC 2012) 上获胜,推广了深度卷积网络以来,卷积神经网络就在计算机视觉中变得无处不在,为了达到更高的精度,整体的趋势就是构建更深的,更复杂的网络。然而,这些提高准确性的改进方法并不一定会在模型规模和运行速度等方面变得高效。在许多现实世界的应用中,例如机器人,自动驾驶汽车,增强现实等,则需要子啊有限计算能力的平台上及时完成识别任务。
本文描述了一种高效的网络架构和一组两个超参数,以建立规模较小,低延迟的模型,可以很容易的匹配移动和嵌入式视觉应用程序的设计需求。第二节回顾了构建小型模型的前期工作。第三节描述了 MobileNets 架构和两个定义更小和更高效 MobileNets 的超参数:宽度乘法因子( width multiplier )和分辨率乘法因子( resolution multiplier )。第四节描述了在ImageNet 上的实验以及各种不同应用和使用案例。第五节以总结和结论结尾。
Prior Work
在最近的工作中,人们开始对构建小型高效神经网络感兴趣。这些不同的方法可以分为 压缩预训练模型 和 直接训练小网络 两种。本文提出了一类网络架构,它允许模型开发人员为他们的应用程序专门选择符合资源限制(延迟,网络规模)的小型网络。 MobileNets 主要专注于优化延迟,但也产生小型网络。许多关于小型网络的的论文只关于规模但是没有考虑到运行速度。
MobileNets 主要由深度可分离网络构建,最初在一个博士论文中,后来在 Inception 模型中使用用于减少前几层的计算。Flattened Networks 构建了一个完全分解的卷积网络,展示了极端分解网路的潜力。与本文无关的是,Factorized Networks 引入了一个类似的分解网络以及使用了拓扑连接。随后,在Xception Networks 演示了如何拓展深度可分离过滤器以超越 Inception V3网络。另一个小型网络是 SqueezeNet,它使用了瓶颈方法(bottleneck approach)去设计小型网络。其他简化计算的网络包括 Structured Transform Networks 和 Deep Fried ConvNets。(吓得我都不敢翻译了)
另一种获取小型网络的方法就是缩小,分解,或者压缩预训练模型。基于 production quantization, hashing, pruning, vector quantization 和 huffman coding 的压缩方法都有文献提及(乘积量化,哈希,剪枝,矢量量化,哈夫曼编码)。此外,还有一些分解方法来加速预训练网络的速度。另一种训练预训练网络的方法是 distillation (蒸馏),它使用较大的网络来训练较小的网络,是本文方法的补充,在第四节的一些用例中也会涉及。另一种新型的方法是 low bit networks(低比特网络)。
MobileNet Architecture
首先描述构建 MobileNets 的核心层,这些核心层由深度可分离过滤器组成。然后描述了 MobileNets 的网络结构,并对两种模型进行描述,即使用宽度乘法因子和分辨率乘法因子的缩小超参数的模型。
Depthwise Separable Convolution
模型基于深度可分离卷积,是一种分解卷积的形式,它将标准的卷积分解为深度卷积和一个 $1\times1$ 的称为点态卷积的卷积。对于 MobileNets, 深度卷积对每个输入通道应用一个滤波器。然后点态卷积会进行一个 $1 \times 1$ 卷积将深度卷积的结果结合起来。一个标准的卷积在一步之内过滤和将输入结合生成一组输出。而深度可分离卷积则将其分为两层,一层用于过滤和一层用于合并。这种分解可以显著减少运算量和模型大小。下图为标准卷积分解为深度卷积和 $1\times1$ 点态卷积的过程。
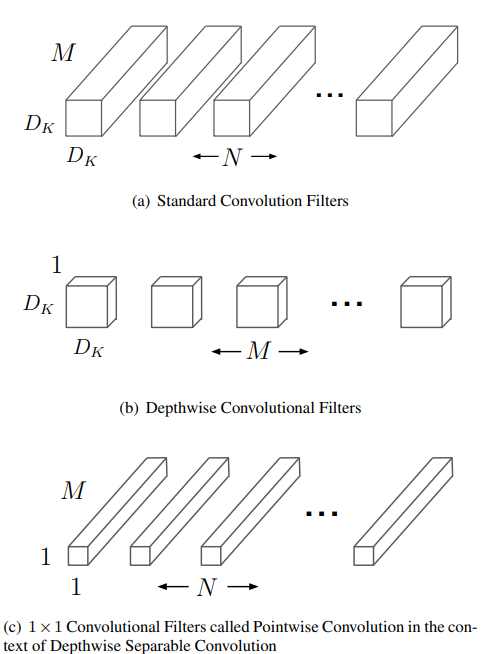
标准的卷积层将一个 $D_F \times D_F \times M$ 的特征图 $F$ 作为输入,并输出一个 $D_F\times D_F \times N$ 的特征图 $G$, 这里的 $D_F$代表特征图的空间宽度和高度,$M, N$ 为通道数,需要注意的是,很显然,这里的$D_F$只是代指,输入和输出的高度和宽度并不可能完全一样,这里只是为了方便分析。
标准的卷积层用卷积核 $K$ 参数化,大小为 $D_K\times D_K\times M\times N$,这里的$D_K$ 为卷积核的空间维度,假设为方形的卷积核,$M,N$ 分别为输入输出的通道数。
对于标准的卷积(假定步长为一并含有填充)的输出特征图则可以计算为:
因此标准的计算代价为:
即依赖于输入的卷积核大小,输入输出通道数,输出的特征图大小。
MobileNets 处理这里的每一项和之间的联系。首先使用深度可分离卷积来打断输出通道数和卷积核大小之间的关系。
标准的卷积操作在卷积核的基础上对特征进行过滤,并结合特征产生新的表示。滤波和组合步骤可以通过分解卷积分为两个步骤,这种分解叫做深度可分离卷积并且可以后续减少计算代价。
深度可分离卷积由于两层构成:深度卷积和点态卷积。使用深度卷积对每个输入通道(输入深度)应用一个简单的滤波器。点态卷积,一个简单的$1\times 1$ 卷积,用来创建深度卷积层输出的线性组合。MobileNets 对这两层都使用了batchnorm 和 ReLU非线性激活函数。
对每一个输入通道(输出通道)使用一个滤波器进行深度卷积可以表达为:
这里 $\hat{K}$ 为深度卷积核,大小为 $D_K \times D_K \times M$ , $\hat{K}$ 第 $m_{th}$ 个滤波器应用在 $F$ 的 $m_{th}$通道,并产生输出特征图 $\hat{G}$ 的第 $m_{th}$ 个通道。
深度卷积的计算代价为:
深度卷积相比标准卷积则非常有效。但是只是对输入的通道进行了滤波,并没有将滤波后的结果结合以产生新的特征。因此需要一个额外的层来计算深度卷积的输出的线性组合,这通过一个 $1 \times 1$ 的卷积来实现以生成新的特征。
深度可分离卷积的代价为:
即深度卷积$1\times1$点态卷积的代价总和。
通过将卷积表达为两个步骤(滤波和组合)可以得到计算代价的减少:
MobileNets 使用了$3 \times 3$ 深度可分离卷积比标准卷积减少 8 到 9倍的计算量,并且精确度只有一点点的下降。
空间维度上的额外分解并没有减少太多的额外计算,因为深度卷积减少了很多的计算量。
Network Structure and Training
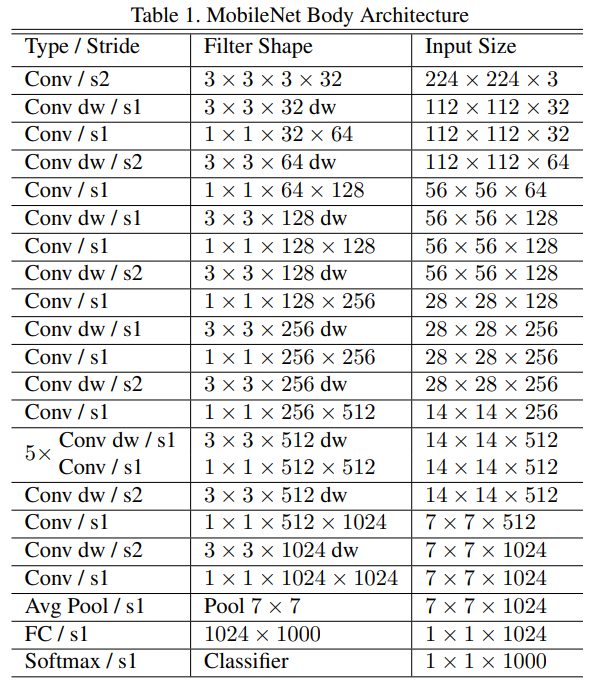
MobileNets 架构是构建在深度可分离卷积的基础上,除了第一层使用仍是全卷积。通过这样定义网络,可以更容易的探索网络拓扑结构来找到一个好的网络。MobileNets体系结构如下所示。所有层后面都有一个 batchnorm 和 ReLU 非线性激活函数,除了最终的全连接层没有非线性函数以外,全连接需要送入 softmax 层来进行分类。
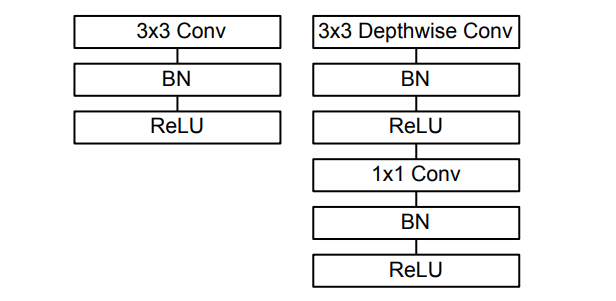
下图对比了标准卷积配有 batchnorm 和 ReLU 非线性激活函数和深度可分离卷积。
下采样通过跨步卷积来处理。在全连接层之前,使用均值池化层将空间分辨率降低到1。将深度卷积和点态卷积看成独立的层,MobileNets 则有28层。
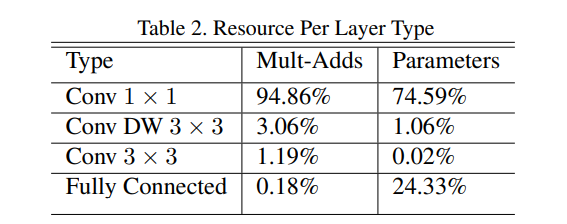
使用少量的 Multi-Adds 定义网络是不够的,还需要保证这些操作可以有效的实现。例如非结构化的稀疏矩阵操作通常并不会比稠密矩阵快,除非达到非常高的稀疏级别。模型结构几乎将所有的计算都放在了稠密的 $1\times 1$ 卷积中,这可以通过GEMM实现。通常卷积是由GEMM实现的,但是需要在内存中进行一个称为 im2col 的操作来将其映射到 GEMM。例如,在Caffe库中,$1\times 1$卷积并不需要预先安排内存而可以直接使用 GEMM实现,这是最优化的数学线性代数算法之一。MobileNets 使用了将近 95% 的时间用于 $1\times1$卷积计算,也有 75% 的参数如下所示。几乎所有的额外参数都在全连接层。
MobileNets 模型在 TensorFlow中使用 RMSprop训练,并采用了类似于 Inception V3的异步梯度下降。然而,与训练大型模型相反,模型使用较少的正则化和数据增强技术,因为小模型有较少的过拟合问题。在训练 MobileNets 时,不使用 side head和label smoothing并且限制在 large Inception training 中使用的切割尺寸,来减少图像失真。此外,还发现,在深度滤波器层中需要使用小的甚至没有权重衰减(L2 正则化),因为他们的参数太少。对于后面的ImageNet基准测试,不管模型的大小,都是用相同的训练参数进行训练。
WidthMultiplier : Thinner Models
尽管基本的MobileNets 体系结构已经很小,并且延迟很低,但是很多时候一个特定的用例可能会要求模型更小更快。为了构建更小的,计算成本更小的模型,引入了一个简单的参数 $\alpha$,称为宽度乘法因子。宽度乘法因子 $\alpha$ 的作用是让网络的每一层均匀的变小。对于一个给定的层和一个宽度乘法因子 $\alpha$,那么输入的通道数将会变成 $\alpha M$,输出的通道数将会变为 $\alpha N$。
那么深度可分离卷积的计算代价将会变成:
这里的 $\alpha \in (0,1]$,通常设置为 1, 0.75, 0.5, 0.25。$\alpha = 1$ 为基线的 MobileNet,$\alpha < 1$ 则为削减的 MobileNet。宽度乘法因子可以近似 $\alpha^2$二次降低计算成本和参数量。宽度乘法因子可以应用于任何模型结构以定义一个新的更小的模型。具有合理的精度,延迟和大小权衡。它可以用于定义新的需要从头训练的简化结构。
Resolution Multiplier: Reduced Representation
第二个用于减少神经网络计算代价的超参数为分辨率乘法因子 $\rho$。将其应用于输入图像上,则每一层的内部表示都会随后以相同的乘法因子缩小。因此,只需要隐式的设置输入分辨率为 $\rho$ 即可。
现在可以将网络的核心层的代价表达为具有宽度乘法因子 $\alpha$ 和分辨率乘法因子 $\rho$ 的深度可分离网络:
这里 $\rho\in (0,1]$。通常隐式设置以使得网络的输入分辨率为 224, 192, 160, 128。$\rho = 1$ 为基线的 MobileNet。$\rho < 1$ 为削减的 MobileNet。分辨率乘法因子将可以使计算代价以 $\rho^2$ 减少。
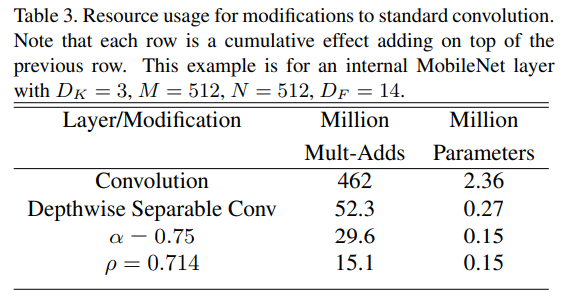
上表显示了结构收缩方法依次应用各个层后的计算量和参数量。输入特征图大小为 $14\times 14 \times 512$, 核大小为 $3 \times 3 \times 512 \times 512$。
Experiments
首先说明深度卷积的效果,以及通过减少网络宽度而不是层的数量来进行网路压缩。然后展示了基于两个超参数:宽度乘法因子和分辨率乘法因子削减网络的权衡,然后研究了应用于不同应用程序的从MobileNets。
Model Choices
首先展示了带有深度卷积网络的模型和使用完全卷积的模型的对比结果。如下表,可以看出,使用深度可分离卷积相比使用完全卷积只会在 ImageNet 上减少 1%的精确度,但是会极大的减少 Multi-adds 和参数。

然后展示带有 宽度乘法因子的 thinner 模型与层数较少的浅模型的对比。为了使 MobileNets 模型更浅,Table1.中的五层独立滤波器(大小为$14 \times 14 \times 512$)被移除。下表展示了在相似的计算量和参数数量下,使MobileNets 更thinner比使其更浅的性能好 3%。
后面的具体实验结果建议直接看论文的图表。






