
MobileNets v3
Searching for MobileNetV3
目标仍然时优化移动设备上的精度延迟权衡(accuracy-latency trade off),引入了一些新的概念:
complementary search technique 互补搜索技术
new efficient versions of nonlinearities practical for the mobile setting 新的高效版本的非线性使用的移动设置
new efficient network design 新的高效的网络设计
new efficient segmentation decoder 新的高效的分割解码器
涉及的其他一些知识。
- swish
- sigmoid $\rightarrow$ hard sigmoid
展望:It remians an open question of how best to blend automatic search techniques with human intuition,即如何将自动搜索技术和人类直觉相结合。
Related Work
总结回顾了一部分网络, 参数数量和 MAdds是不同的概念,MAdds和参数数量的关系不是严格的相等。
SqueezeNet: 广泛使用 $1\times 1$ 卷积,squeeze 和 expand模块来减少参数数量
MobileNet v1: 使用深度可分离卷积(depthwise deparable convolution)来提高卷积计算的效率
MobileNet v2: 引入了反向残差连接(inverted residuals)和线性瓶颈(linear bottlenecks)来构建高效资源块
下面的几个目前我还没读
ShuffleNet: 使用了组卷积(group convolution)和通道打乱(channel shuffle)进一步降低MAdds
CondenseNet: 在训练阶段学习组卷积,以保持层之间有用的密集连接,以便特征重用(feature re-use)。
ShiftNet: 提出了与逐点卷积交错的移位操作(shift operation)来代替空间卷积(expensive)。
上面三个后续如果有需要再进行补充。
随后提到了结构设计的问题,相关论文在参考文献自寻。
为了实现结构设计过程的自动化,RL被引入到了搜索具有挑战的高效的架构中,但是搜索空间可能是指数级增长并且难以处理。因此早期的架构搜索都是集中在了单元级别的结构搜索,同一单元在所有层重用。MnasNet 搜索一个块级分层搜索空间,允许网络在不同分辨率块上使用不同的层结构。为了减少搜索的代价,[…]使用了差分(differentiable)结构搜索框架,并进行了基于梯度的优化(gradient-based optimization)。为了使现有网络适用于受限的移动平台,[…]提出了更高效的自动化网络简化算法。
[…]量化(Quantization)是通过降低算术精度来提高网络效率的一个补充方法,[…]知识蒸馏(distillation)提供了一个额外的补充方法,可以在大的 “teacher”网络下训练精确的小”student”网络。
[…]涉及的论文目前没有看过,自行在论文中查找。
Efficient Mobile Building Blocks
MobileNet v1和MobileNet v2说累了,这里跳过了。
MnasNet 建立在MobileNet v2结构之上,在瓶颈结构中引入了基于挤压(squeeze)和激励(excitation)的轻量化注意力模块(attention)。挤压和激励模块集成在不同的位置,而不是像基于ResNet的模块。模块放置在扩展层(expansion)的深度过滤器模块(depthwise filters)之后,以便注意力应用于下图中的最大表示。
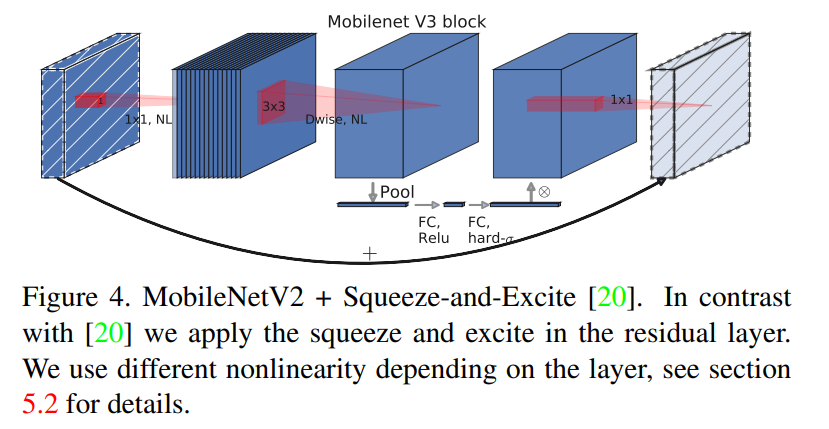
对于MobileNet v3,使用了这些层的组合来构建块以便于构建最有效的模型,并且每一层还是用改进的 Swish激活函数,挤压和激励模块以及swish都是用 sigmoid,这个在计算上效率是低下的,并且在固点算法中保持精度,因此将其替换成了 hard sigmoid.
NetWork Search
网络搜索时探索和优化网络架构中的一个非常强大的工具[…],对于MobileNet v3,使用了平台感知的NAS,通过优化每个网络来搜索全局网络结构,然后使用了NetAdapt算法来搜索每一层的过滤器数量。这些技术是互补的,并且可以结合起来有效地找到针对于给定硬件平台的优化模型。
Platform-Aware NAS for Block-wise Search
这里直接使用了 MnasNet-A1来作为初始的大型移动模型(因为使用了和 MasNet相同的基于rnn的控制器和相同的分解层次搜索空间,所以结构肯定类似,于是直接重用了?并不理解表达的意思),然后在其上应用 NetAdapt和其他的优化算法。
但是最初的奖励函数的设计并没有针对小型移动模型进行优化,具体的来说,它使用的是多目标的奖励函数:$ACC(m)\times[LAT(m)/TAR]^w$ 来近似帕累托最优解(Pareto-optimal solutions),并基于每个目标延迟 $TAR$ 对每个模型 $m$ 平衡模型精度 $ACC(m)$ 和延迟 $LAT(m)$。对于小模型,精度随延迟的变化显著,因此需要一个更小的权重因子 $w = -0.15$ (origin = -0.07),以补偿不同延迟下较大的精度变化。在新的权重因子 $w$的增强加,从头构建一个新的架构,以找到一个初始种子模型,然后应用 NetAdapt和其他优化手段来获得最终的 MobileNetV3-Small模型。
NetAdapt for Layer-wise Search
架构搜索中使用的第二个技术是 NetAdapt,这是对平台感知的NAS的补充,它允许以顺序的方式微调各个层,而不是试图推断粗糙但全局的架构。具体可看原文。简而言之,这个过程是这样运行的:
- 首先从平台感知的NAS找到的种子网络架构开始
- 然后对于每一步:
- 生成一组proposals,每个proposal 代表了对体系结构的修改,与前一步相比,延迟至少减少了 $\delta$
- 对于每个proposal,使用前一步中得到的预训练的模型,并填充新提出的架构,适当的裁剪和随机初始化缺失的权值。对每一项proposal进行微调 $T$ 次,以得到精度的粗略估计。
- 根据指标选出最佳的proposal。
- 迭代每一步直到达到目标延迟。
原文中的评价指标是最小化精度的变化。这里对该算法进行改进,使延迟变化和精度变化比例最小化。也就是说,对于 NetAdapt中的每一步中生成的所有的proposals,选择其中最大化 $\frac{\Delta Acc}{\Delta latency}$ 的一项,并且满足 $\Delta Acc$ 满足前面提到的 $\delta$ 减少的限制。直觉上,proposal 是离散的,因此更倾向于能够使 trade-off 曲线斜率最大的 proposal。
这个过程重复进行,直到达到目标的延迟,然后从头开始训练新的体系结构。对 MobileNet v2使用与原始 NetAdapt相同proposal生成器。具体来说,允许两类proposals。
- 减少 expansion layer的尺寸
- 减少所有共享相同 bottleneck 大小的块中的 bottleneck——以保持残差连接。
实验中设置 $T = 10000$,虽然增加了初始微调的准确性,但是从零开始训练时,它不会改变最终结果的准确性。设置 $\delta = 0.01|L|$,这里 $L$ 是种子模型的延迟。
NetWork Improvement
除了 Network Search外,还在模型中引入了几个组件以改进最终模型。
- 在网络的开始和结束部分重新设计计算开销较大的层
- 引入一种新的非线性函数 h-swich,是swich的改进,计算速度更快,也更适合量化
Redesigning Expensive Layers
架构搜索找到模型之后,网络的开始和结束部分的很多层的计算代价很高,因此对模型架构进行了修改来减少这一部分层的延迟,同时保持正确性。这些改进是在当前搜索空间以外的。
第一个修改改进了网络最后几次的交互,以便更有效地生成最终的特征。目前基于MobileNetv2地inverted bottleneck 结构和变种地模型使用 $1\times 1$卷积作为最后一层,以扩展到更高维度地特征空间。这一层是至关重要的,为了能够获得更富集的特征用于预测,然而吗,这是以额外的延迟为代价的。
为了减少延迟并保留高维的特征,将这一层移到了最后的平均池化层。最后的一组特征将以$1\times1$ 的空间分辨率计算而不是 $7\times 7$空间分辨率。这种设计选择的结果是,特征的计算在计算和延迟方面上几乎free。
一旦减轻了特征生成层的计算代价,就不需要使用之前的bottleneck projection 层来减少计算量。从而可以移除前面bottleneck层中的projection和filtering层,进一步降低计算复杂度。原始和优化后的最终阶段图下所示。有效的最后阶段减少了7ms的延迟,这是运行时的11%,减少了3000层MAdds的操作数量,并且几乎没有降低正确性。
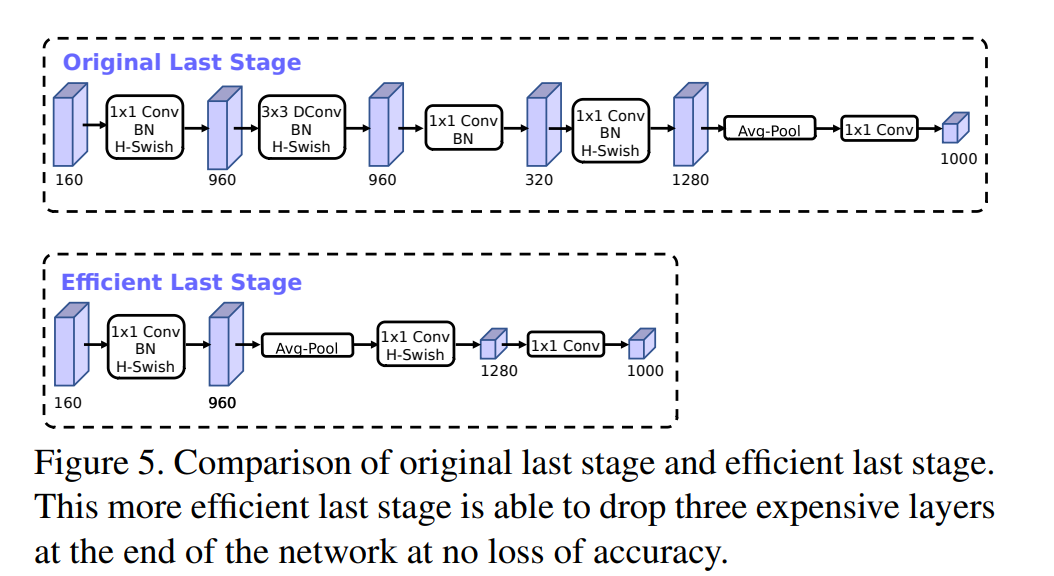
另一个计算代价高的层就是初始的一组滤波器。目前的移动模型倾向于在一个完整的 $3\times 3$ 卷积中使用 32个
滤波器来构建边缘检测的初始滤波器组。这些滤波器通常是彼此的镜像。尝试减少滤波器的数量,使用不同的非线性来尝试减少冗余。最后选定在这一层使用 hard swish非线性函数,因此在测试中它的性能其他非线性相当。可以将滤波器的数量减少到16个,同时使用 ReLU或 swish保持与 32个滤波器相同的精度。这额外减少了2ms 的运行时和 1000万的MAdds计算量。
Nonlinearities
[…]引入了 swish 非线性函数把他作为 ReLU的临时替代,并且显著提高了神经网络的准确性。这个非线性函数定义为:
尽管这种非线性提高了精度,但是它在嵌入式环境中的代价非零,因为在移动设备上计算 sigmoid函数代价较高。使用两种方法来处理这个问题:
类似于[..],将sigmoid函数替换为它的分段线性硬模拟函数: $\frac{ReLU6(x+3)}{6}$, 最小的区别就是使用 ReLU6而不是传统的裁剪常量。类似的,硬版本的 swish 就变成了:
[…]也提出了一个版本的hard-swish。 sigmoid和swish的对比图如下所示。
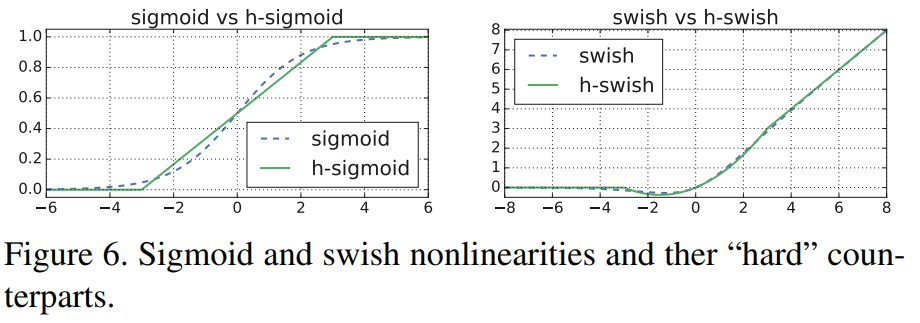
常量的选择动机就是简化并且尽可能好的匹配原始版本。实验中发现所有这些功能在 hard 版上的准确性没有明显的差异,但是在部署的角度上却有很多优势:
- 在几乎所有的软硬件框架下都有ReLU6的优化实现
- 在量化模式下,消除了由于不同的近似 sigmoid实现可能造成的数值精度损失
- 在实践中,h-swish 可以实现为分段函数来减少内存访问的次数,从而大大降低延迟的成本
应用非线性函数的代价会随着网络的深入而降低,因为每一层的激活体内存会在分辨率下降时减半。只有在更深的层次中使用才可以实现 swish 的大部分的优势。因此,在网络架构的后半部分使用h-swish,具体的网络布局如下所示。
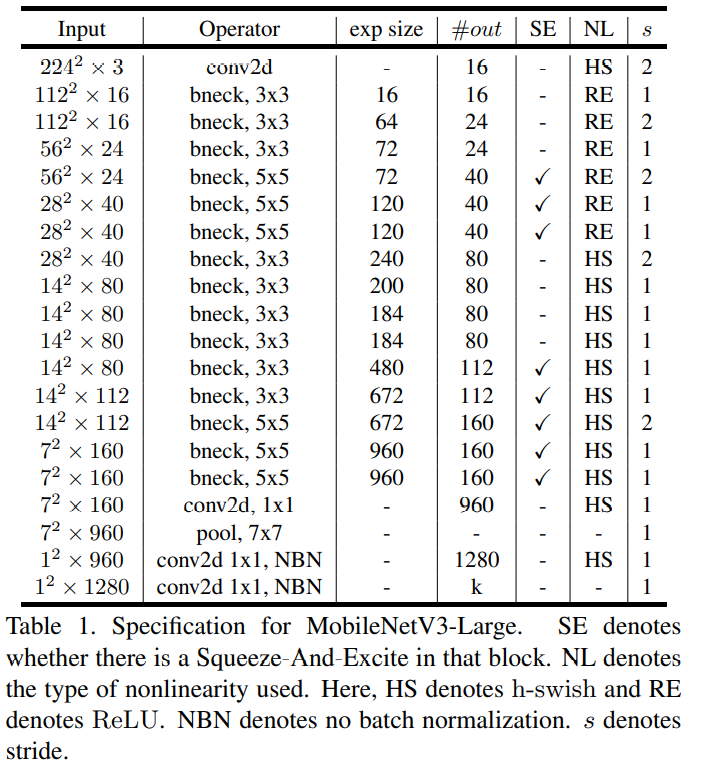
MobileNetV3 Large
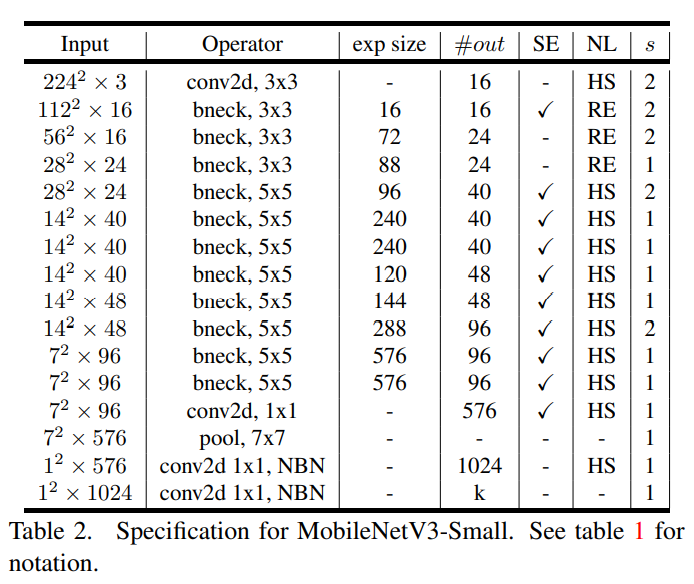
MobileNet V3 Small
尽管有了这些优化,h-swish仍然会带来一些延迟代价。后面的实验演示中说明了,网络对精确度和延迟上,在没有优化的情况下是积极的,在使用基于分段函数的优化实现时,影响是显著的。
Large squeeze-and-excite
MnasNet中,squeeze-and-excite bottleneck的大小与 convolution bottleneck相关。相反,这里将他们全部替换为固定,使其为 expansion层的 $1/4$,这样做可以在增加参数数量的情况下提高准确性,并且没有显著的延迟代价。
MobileNetV3 Definitions
MobileNetV3 定义为两个模型:MobileNetV3-Large和MobileNetV3-Small,这两个模型分别用于高资源和低资源用例。这些模型通过平台感知NAS和NetAdapt进行网络搜索,并结合定义的网络改进方法来创建。具体见Table 1&Table 2。






