
FastFlowNet
代码开源了个寂寞,不过无所谓,只是看看他做了什么而已。官方链接
非常 amazing 的地方在于 FastFlowNet 只包含 1.37M 的参数,并且 fps 很不错。
Abstract
FastFlowNet 仍然使用了广泛应用的 coarse-to-fine 策略,此外还有以下几个创新点。
使用了一个 head enhanced pooling pyramid (HEPP) 特征提取器,在减少参数的同时增强了高分辨率的金字塔特征。
引入了一个 center dense dilated correlation (CDDC)层 用于构建紧凑的代价体,并且可以保持较大的搜索半径下减少计算量。
在每个金字塔层中植入了一个有效的 shuffle block decoder (SBD) 用于加速光流估计,不过边缘精度有所下降。但是相比同样精度的网络,只需要 $1/10$ 的计算量。
FastFlowNet 只含有1.37M 个参数,对于一个分辨率为 $1024\times436$ 的Sintel图片,在单个 GTX 1080Ti 下可以做到 90 FPS,嵌入JetSon TX2 GPU 可以做到 5.7 FPS。
INTRODUCTION&& RELATED WORK
这部分说的很牛逼,后面写论文可以参考。
Method
OverView of the Approach
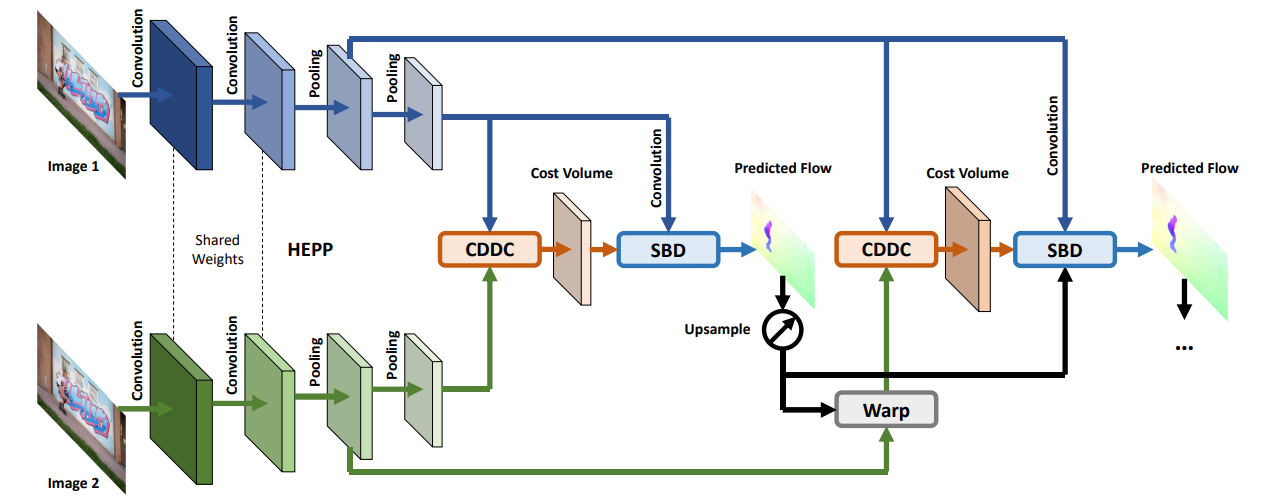
给定两个时间域相邻的输入图片$I_1,I_2 \in \mathbb{R}^{H \times W \times 3}$, 提出的 FastFlowNet 模型将会利用由粗到细的残差结构来逐渐估计精化后的光流 $F^{l} \in \mathbb{R}^{H^l \times W^l \times 2}, l = 6,5,\cdots,2.$ 但是通过修改去减少参数和计算代价来加速推理。为此,首先替换了 PWC-Net 网络中的对偶卷积特征金字塔为 头增强的池化金字塔 (head enhanced pooling pyramid) 来增强高精度分辨率的金字塔特征和减少模型的尺寸。在此基础上,提出了一种新得中心密集扩张相关层(center dense dilated correlation layer),在保证大的搜索半径得前提下,构造紧凑得代价体。最后,在每个金字塔层使用新的shuffle 块译码器 (shuffle block decoders) 来回归计算光流。模型的结构细节如下所示。

Pool: average pooling
Fconv5_2, Fconv5_3, Fconv5_4: convolutions with group = 3
Shuffle: channel shuffle operation
除了 upconv6 和 fconv5_7 的卷积层都后接 LeakyRELU 激活函数
Head Enhanced Pooling Pyramid
传统的方法在光流估计上应用图像金字塔来加速优化和处理大尺度位移。SpyNet 转换这种经典的范式并首次引进了基于图像金字塔的池化用于加深模型。因为原始图像对光影变换时敏感的,因此固定的池化金字塔对噪声,例如阴影和反射等是不足的。PWC-Net, LiteFlowNet,使用可学习的特征金字塔替代图像金字塔,带来了很大的改进。具体地说,在减少空间尺寸的同时逐步扩张特征通道数来提取鲁棒的匹配特征。
低分辨率下的较大的通道数会导致大量的参数,对于由粗到细的方案来说可能是冗余的,因为低层的金字塔特征可能只会对估计粗糙的流域有用。因此,模型结合了高层的特征金字塔结构和低层的池化金字塔兼顾两个优势。另一方面,高分辨率下的金字塔特征在PWC-Net中相比较浅,因为每个金字塔层只包含两个卷积核大小为 $3 \times 3$ 的卷积层,因此其感受野较小。因此模型花费了一点额外代价在高层添加了一个额外的卷积层来增强金字塔特征。通过平衡不同尺度下的计算,文章提出了HEPP,和 FlowNetC, PWC-Net 和 LiteFlowNet 一样, HEPP会生成 6个金字塔层从 $1/2$ 分辨率(第一层) 到 $1/64$ 分辨率(第六层),缩放因子为 2。
Center Dense Dilated Correlation
现代的光流估计架构中的一个重要的步骤就是通过基于卷积层的内积来计算特征一致性。对于金字塔 $l$ 层的两个特征 $f^l_1, f^l_2$ ,类似很多由粗到细的残差方法,首先使用了基于 warping 的双线性插值,根据 $2\times$前面的流场的上采样的结果 $up_2(F^{l+1})$ 对第二个特征 $f^l_2$ 进行 warp。warp 的目标特征 $f_{warp}^l$ 可以极大的减少由于大尺度运动带来的位移,这将有益于减少搜索区域和简化任务为估计相对较小的残差流。最近的工作 PWC-Net,LiteFlowNet 通过在局部方形区域内相关源特征和对应的warped后的目标特征构建代价体,可公式化为:
$x, d$ 代表空间和偏移坐标,$N$ 为输入特征的长度,$r$ 为搜索半径,$\cdot$ 代表点积。
已有的工作PWC-Net等已经表明,在构建代价体时增加搜索半径可以在训练和测试中降低 EPE 误差,尤其对于大位移的情况。但是代价体的特征通道时搜索半径的平方级,后续的解码器网络的计算复杂度将会变成四次方。
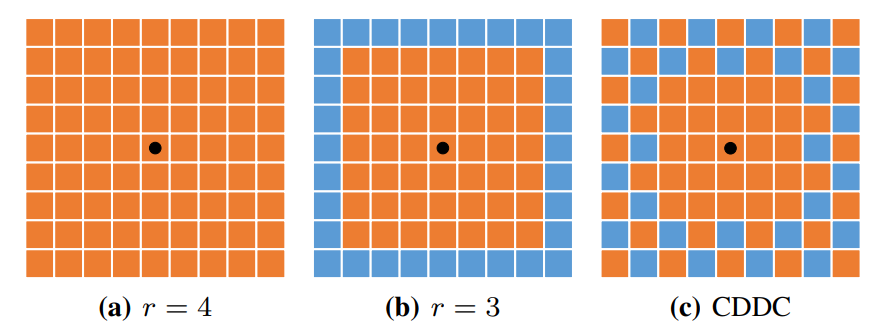
如图 $a$,很多的光流网络设置 $r = 4$,庞大的计算量阻碍了低功耗应用的发展。一种简单的方法就是减小半径 $r$。例如设置 $r = 3$, 如图 $b$。从而使代价体特征从 81 减少到 49. 但是这种办法的代价是牺牲了感知范围和精度。
受到 DeepLabv3 的 atrous spatial pyramid pooling(ASPP) 的启发,提出了CDDC层在大运动区域内下采样网格点时,在中心周围密集搜索格点,如图 $c$ 所示。
与 ASPP 使用并行 atrous 卷积来获取多尺度上下文信息不同,提出的 CDDC 旨在减少构建大半径代价体时的计算量。在 FastFlowNet 中,会输出 53 个特征通道,与传统的 $r=3$ 设置类似。动机在于残差流会更关注小运动。实验证明 CDDC 方法比传统的压缩方法更优。
Shuffle Block Decoder
在构建代价体后,由粗到细的模型通常会将上下文特征,代价体量和上采样的前一个光流结果 concatenate起来,作为后面解码器的输入。在每一个金字塔层,解码器会占用整个网络的大部分参数和计算量。因此,更好的速度和精度的权衡时至关重要的。
PWC-Net表明,稠密连接的流解码器在对 FlyingThing3D 数据集进行微调后,可以提高解码器的精度,但代价是增加了模型大小和计算量。LiteFlowNet 使用了顺序连接的流估计器,并且显示出了更好的性能。为了达到两种方案的权衡,FDFlowNet使用了部分全连接结构。这些方法都不能在嵌入式系统中进行实时的推理。
由于 CDDC 构建的紧致代价体,可以直接将解码器网络的最大通道数从 128 减少到 96个。为了进一步减少计算量和模型的大小,将中间的三个96通道的卷积转换为组卷积,然后进行通道 shuffle 操作,称之为 Shuffle Block。与ShuffleNet 作为骨干网络不同的是,shuffle 译码器用于光流的回归。
每个解码器网络包含了三个 $group = 3$ 的 shuffle 块,这有效的减少了计算量,但是精度略有下降。
Loss Function
由于 FastFlowNet 采用了 和 FlowNet 和 PWC-Net 相同的金字塔结构,因此采用了同样的多尺度 $L2$ 损失函数用于训练。
这里 $|\cdot|_2$ 计算预测光流和真实光流之间的 $L2$ 范数。
在有真实场景结构的数据集上进行微调时,例如 KITTI 数据集,使用了如下的鲁棒损失函数:
这里的 $|\cdot|$ 表示 $L1$ 范数,$\epsilon = 0.01$ 表示一个很小的常数,$q \lt 1$ 使的对大的异常值更加鲁棒。为了与以前的方法(FlowNet, SPyNet, PWC-Net, LiteFlowNet)公平对比,将公式(2)(3)中的权重设置为$\alpha_6=0.32,\alpha_5=0.08,\alpha_4=0.02,\alpha_3=0.01,\alpha_2=0.005$.
Experiments
Implements Details
为了将 FastFlowNet与其他网络进行对比,遵循了 FlowNet2 中提出的两阶段训练策略。真实的光流值除以20,并且下采样作为不同层的监督信号。由于最终的预测的分辨率为 $1/4$ ,因此使用了双线性插值来获得全分辨率的光流。在训练和调试阶段,使用了和 FlowNet 同样的数据增强方式,包括镜像翻转,平移,旋转,缩放,挤压和颜色抖动。实验在PyTorch环境下实现,并且在装有 4 张 Nvidia GTX 1080 Ti GPU卡的机器上进行。为了比较不同的光流模型在移动设备上的性能,进一步在嵌入式的Jetson TX2 GPU上测试了推理时间。
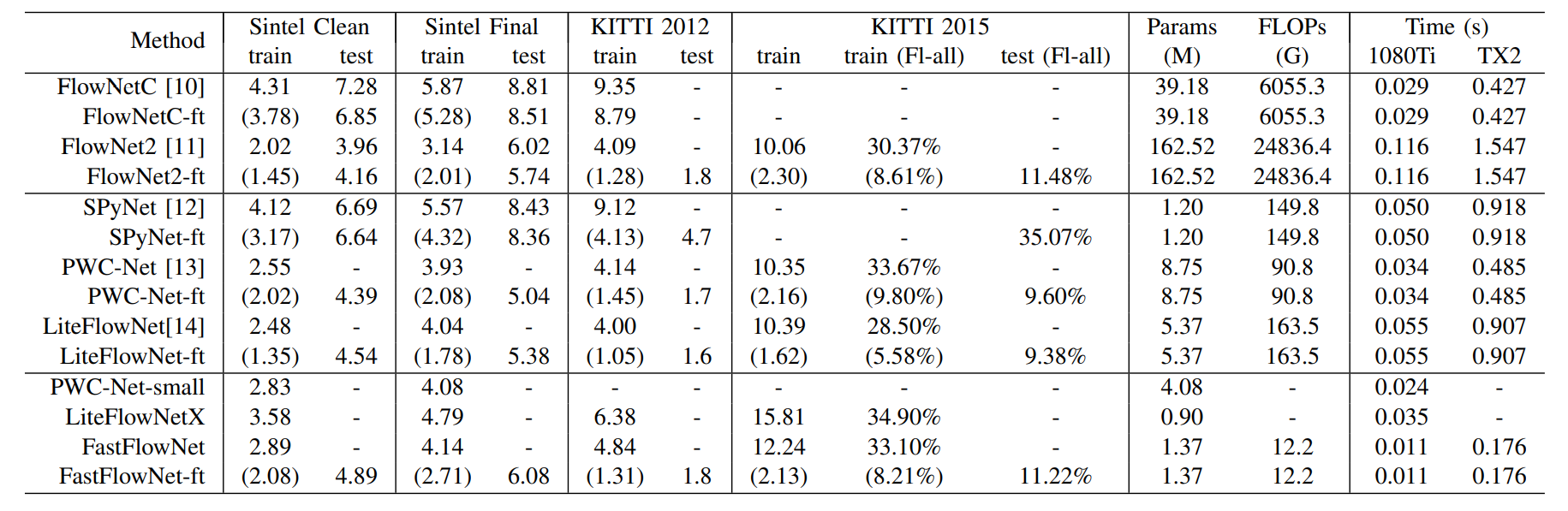
首先在 FlyingChairs 数据集上训练,使用 $S_{short}$ 学习计划。初始学习率为 $1e^{-4}$,并在30w, 40w, 50w次迭代的时候衰减一半。在数据增强阶段随机裁剪出 $320 \times 448$ 的 patch,并采用 $batch-size = 8$ 。模型在 FlyingThings3D 数据集上进行微调,并采用 $S_{fine}$ 学习计划。学习率初始化为 $1e^{-5}$, 并且在 20w, 30w, 40w迭代的时候衰减一半。随机切割尺寸为 $384 \times 768$,并且 $batch-size = 4$。 使用 $Adam$ 优化器和多尺度的 $L2$ 损失函数。在 Sintel 和 KIITI 的训练集结果如下所示。
Ablation study
暂时略,需要时再补充






